
Are you wondering what are the top substitutes for ChatGPT? We will share some of the top options to help you narrow your search.
Although ChatGPT has swiftly emerged as the generative AI industry’s favourite, it is far from the only competitor. There are a lot of direct competitors with ChatGPT, in addition to all the other available AI tools that perform tasks like image generation, or at least that’s what I imagined.
Why not inquire about it on ChatGPT? I did that to obtain this list to locate some possibilities for people receiving “at capacity” notices or others wanting to try something new. These are the best options. However, not all of them are as open to the general public as ChatGPT.
The Top Substitutes For ChatGPT
1) Bing Chat By Microsoft
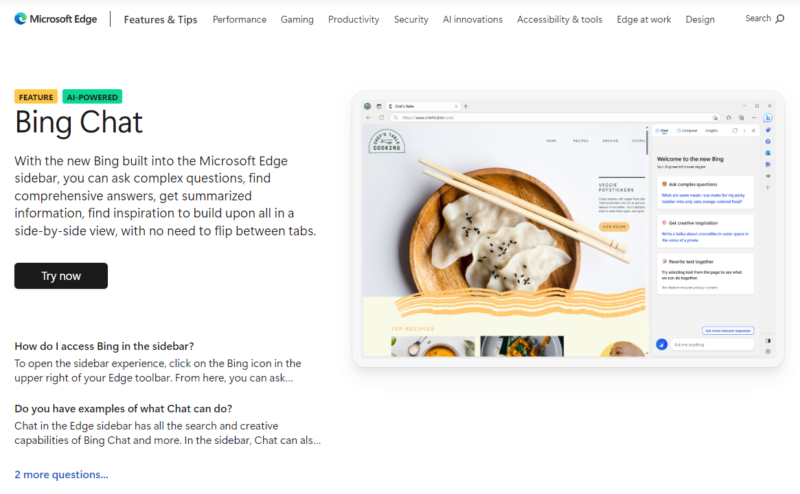 Before discussing the choices made by the AI, ChatGPT itself is the ideal substitute. Recently, Microsoft integrated artificial intelligence into its Bing search engine, and it soon wants to roll out the feature to the Edge browser.
Before discussing the choices made by the AI, ChatGPT itself is the ideal substitute. Recently, Microsoft integrated artificial intelligence into its Bing search engine, and it soon wants to roll out the feature to the Edge browser.
Even though it’s still in preview, you may currently test out the new AI chatbot at bing.com/new. Although Microsoft claims to be initially restricting the number of queries, you can sign up for the Bing ChatGPT waitlist to be informed when the full version becomes available.
2) BERT By Google
Google created the machine learning model BERT (Bidirectional Encoder Representations from Transformers). Many Google projects were referenced in ChatGPT’s results, which you’ll see later in this list.
BERT is renowned for its natural language processing (NLP) skills, which include sentiment analysis and question-answering. For pretraining references, it refers to the English Wikipedia and BookCorpus, which have amassed 800 million and 2.5 billion words, respectively.
In October 2018, BERT was originally introduced as an academic publication and open-source research initiative. Google Search has since included the technology. Early BERT literature contrasts it with OpenAI’s ChatGPT from November 2018, pointing out that Google’s solution is deeply bidirectional and aids in text prediction. OpenAI GPT, in contrast, can only answer complicated questions and is unidirectional.
3) Meena By Google
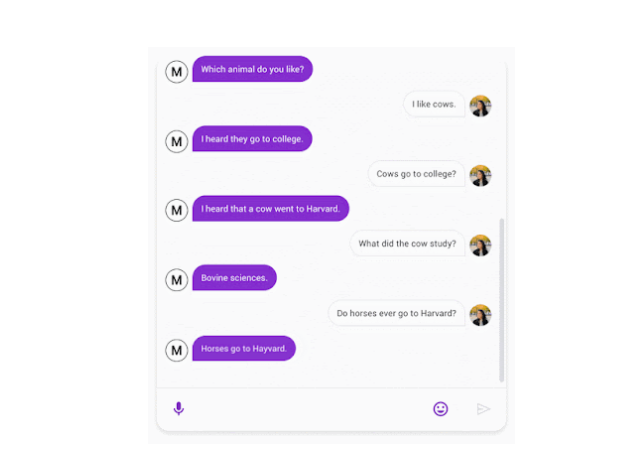
Meena is a chatbot with humanlike conversational capabilities that Google unveiled in January 2020. Simple talks with amusing puns and quips, like Meena’s suggestion that cows study “Bovine sciences” at Harvard, are examples of its functions.
Meena could analyze 8.5 times as much data as its rival at the time, OpenAI’s GPT-2, and was a direct competitor. The neural network has 2.6 parameters and was trained using social media talks from the public domain. Meena was one of the most intelligent chatbots, with a Sensibleness and Specificity Average (SSA) score of 79%.
4) RoBERTa By Facebook
In July 2019, Facebook released RoBERTa (Robustly Optimized BERT Pretraining Approach), an upgrade to the original BERT.
This NLP model was developed by Facebook using a larger data set as its pretraining model. As part of its 76GB data set, RoBERTa employs CommonCrawl (CC-News), which contains 63 million English news stories created between September 2016 and February 2019. Facebook claims that the original BERT used 16GB of data for its English Wikipedia and BookCorpus data sets, in contrast.
According to Facebook’s research, RoBERTa outperformed BERT in benchmark data sets from Silimar to XLNet. The organization trained its model for longer and employed a larger data source to achieve these findings.
In September 2019, Facebook made RoBERTa open-source, and the community can play with the code on GitHub. GPT-2 was among the emerging AI systems at the time that VentureBeat also recognized.
5) XLNet By Google
A group of Carnegie Mellon University and Google Brain academics developed the transformer-based autoregressive language model known as XLNET. The model debuted for the first time in June 2019 and is essentially a more sophisticated BERT.
The team discovered that XLNet was at least 16% more effective than the original BERT, unveiled in 2018. XLNet also outperformed BERT in a test involving 20 NLP tasks.
BERT and XLNet use “masked” tokens to predict hidden text, but XLNet is more effective since it can quickly predict hidden text. For instance, according to Aishwarya Srinivasan, a data scientist for Amazon Alexa,
XLNet can recognize the word “New” as being related to the phrase “is a city” before anticipating the term “York” as being similarly associated. BERT must distinguish the terms “New” and “York” independently and then link them to the phrase “is a city,” for instance.
Incidentally, GPT and GPT-2 are examples of autoregressive language models in this explainer from 2019.
On GitHub, you can find the XLNet source and pre-trained models. The NLP research community is familiar with the paradigm.
6) DialoGPT BY Microsoft Research
Microsoft Research released an autoregressive language model called DialoGPT (Dialogue Generative Pre-trained Transformer) in November 2019. The model was trained to produce humanlike discourse and shares characteristics with GPT-2. Nonetheless, 147 million multi-turn conversations from Reddit threads served as its main data source.
Cobus Greyling, the lead evangelist for HumanFirst, has acknowledged his achievement in integrating DialoGPT into the Telegram messaging platform to make the model a chatbot. Using Amazon Web Services and Amazon SageMaker, he continued, can aid in optimizing the code.
On GitHub, the DialoGPT code is accessible.
7) Albert By Google
Google created ALBERT (A Lite BERT), a condensed version of the original BERT, in December 2019. By incorporating parameters with “hidden layer embeddings,” Google used ALBERT to restrict the number of parameters that could be included in the model.
Because ALBERT can be trained on the same bigger data set of information used for the two newer models while adhering to lower parameters, this improved not just on the BERT model but also on XLNet and RoBERTa.
ALBERT performs its duties using only the required parameters, improving performance and accuracy. According to Google, ALBERT outperformed BERT on 12 NLP benchmarks, including a reading comprehension score akin to the SAT.
GPT is included in the imaging for the ALBERT on Google’s Research blog, albeit it isn’t mentioned by name. In January 2020, Google made the System open-source, built on top of Google TensorFlow. On GitHub, the code is available.
8) T5 By Google
An NLP model called T5 (Text-to-Text Transfer Transformer) was released by Google in 2019 and is based on various earlier models, including GPT, BERT, XLNet, RoBERTa, and ALBERT, among others.
In contrast to the Common Crawl web scrapes used for XLNet, it introduces a brand-new and distinctive data set called Colossal Clean Crawled Corpus (C4), enabling the transformer to deliver higher-quality and contextual results than previous data sets.
The AI Dungeon game and InferKit Speak To Transformer are two examples of chatbot applications made possible by the T5 pretraining. The text generators are similar to ChatGPT in that you may create realistic discussions using the AI’s output following your initial prompts or inquiries. On GitHub, the T5 code is accessible.
9) CTRL BY SALESFORCE
When Salesforce unveiled it in September 2019, CTRL (Computational Trust and Reasoning Layer) was one of the most significant language models publicly available. The 1.6 billion-parameter language model can simultaneously evaluate huge text corpora, like those found on web pages. A few possible practical applications are combined with reviews, ratings, and attributions.
The CTRL language model can tell the purpose of a particular inquiry right down to the punctuation. Due to the variation in the period in the two phrases, Salesforce highlighted that the model could distinguish between “Global warming is a lie.” as an unpopular opinion and “Global warming is a lie” as a conspiracy theory and create appropriate Reddit posts for each.
CTRL uses up to 140GB of data from websites like Wikipedia, Project Gutenberg, Amazon customer reviews, and Reddit for pretraining. Also, it references other sources of global news, facts, and information. On GitHub, the CTRL code is accessible.
10) GSHARD BY GOOGLE
In June 2020, Google unveiled GShard, a mammoth language translation model designed to scale neural networks. Large data sets can be trained using the model’s 600 billion parameters simultaneously. GShard has been trained to translate 100 languages into English in four days and is extremely skilled.
11) BLENDER BY AI FACEBOOK RESEARCH
Facebook AI Research released the open-source chatbot Blender in April 2020. Compared to competing models, the chatbot has been recognized to have better conversational abilities. It can offer interesting discussion points, listen and demonstrate knowledge of its partner’s input, and display empathy and personality.
Blender has been likened to OpenAI’s GPT-2 and Google’s Meena chatbot. You may access the Blender code on Parl.ai.
12) PEGASUS BY GOOGLE
Facebook AI Research released the open-source chatbot Blender in April 2020. Compared to competing models, the chatbot has been recognized to have better conversational abilities. It can offer interesting discussion points, listen and demonstrate knowledge of its partner’s input, and display empathy and personality.
Blender has been likened to OpenAI’s GPT-2 and Google’s Meena chatbot. You may access the Blender code on Parl.ai.
Conclusion
Whether looking for natural language understanding, content generation, summarization, or question answering, the rapidly expanding universe of AI language models offers a treasure trove of options.
When selecting an alternative, it’s crucial to consider factors such as access, scalability, training data
We hope this post helped you find the top substitutes for ChatGPT.